Various Sequence To Sequence Architectures
Basic Models
Sequence to sequence model: input을 다 넣고 output을 받는다. encoder + decoder
Picking the Most Likely Sentence
Language model 같은 경우 input이 들어가고 output이 나오는 것이 동시에 일어난다.
하지만 seq2seq를 이용한 machine translation 같은 경우 input을 넣는 부분과 output이 나오는 부분이 분리되어 있다.
Conditional language model이라고도 부른다. \( P( y^{<1>} ... y^{<T_y>} | x^{<1>} ... x^{<T_x>} ) \)
greedy 하게 가장 확률이 높은 단어를 선택하는 것은 최종적으로 좋은 선택이 아닐 수도 있다.
Beam Search
먼저 beam width를 설정한다.
그런 다음, layer를 깊게 들어가면서 beam depth개의 가장 확률이 높은 candidate를 계속해서 추적한다.
Refinements to Beam Search
length normalization을 위해 \( \text{arg max} \prod_{t=1}^{T_y} P(y^{<t>} | x, y^{<1>}, ..., y^{<t - 1>} ) \)를 \( \frac{1}{T_y^\alpha} \sum_{t = 1}^{T_y} \text{log} P( y^{<t>} | x, y^{<1>}, ..., y^{<t - 1>} ) \)를 계산한다.
이러한 normalization을 통해 더 긴 문장을 generate할 것을 기대해볼 수 있다.
For beam width B, large B -> better result, slower, small B -> worse result, faster
Error Analysis in Beam Search
machine translation에 대해서, 번역된 human sentence \( y* \)와 algorithm이 generate한 sentence \( \hat{y} \)가 있다고 했을 때의 error analysis이다.
case 1: \( P(y* | x) > P(\hat{y} | x) \), beam search에서 문제가 있다.
case 2: \( P(y* | x) \leq P(\hat{y} | x) \), RNN model에 문제가 있다.
Bleu Score
machine translation같은 경우 human sentence와 machien translation sentence가 뜻이 같아도 다른 형태를 띌 때가 있다.
따라서 human sentence와 machine translation sentence가 얼마나 비슷한지를 수치로 나타내기가 어렵고, 이러한 경우
Bleu(BiLingual Evaluation Understudy) score를 사용한다.
\( p_n \) = Blue score on n-grams only
Conbined Bleu score: \( BP \text{exp}(\frac{1}{k} \sum_{n = 1}^k p_k) \) (BP : Brevity Penalty)
BP = min(exp(1 - reference_output_length / MT_output_length), 1)
Attention Model Intuition
seq2seq model 같은 경우 length가 길어질수록 Bleu score가 낮아지는 것을 확인할 수 있다.
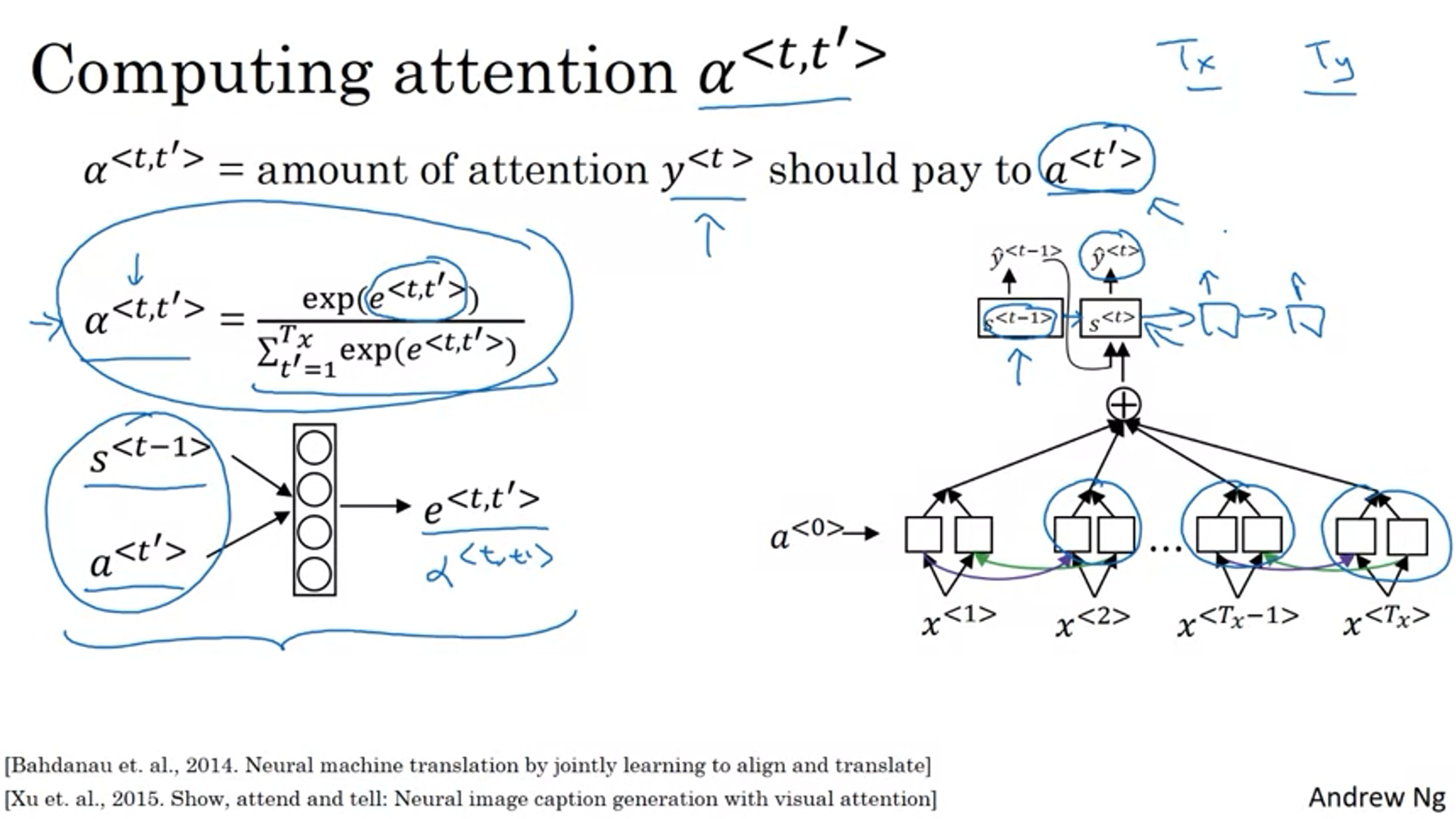
사람이 translation을 하는 것처럼 input의 어떤 단어가 output의 어떤 단어에 강하게 영향을 주는지 weight를 통해 조절하는 model을 attention model이라고 한다.
Attention Model
weight는 이런 식으로 구한다.
'Google Machine Learning Bootcamp 2022 > Sequence Models' 카테고리의 다른 글
| 4. Transformer Network (0) | 2022.08.16 |
|---|---|
| 3. Sequence Models & Attention Mechanism #2 (0) | 2022.08.15 |
| 2. Natural Language Processing & Word Embeddings #3 (0) | 2022.08.12 |
| 2. Natural Language Processing & Word Embeddings #2 (0) | 2022.08.12 |
| 2. Natural Language Processing & Word Embeddings #1 (0) | 2022.08.12 |
댓글