Neural Network Representation
input layer와 output layer을 제외한 나머지 layer를 hidden layer라 부른다.
input layer를 제외한 hidden layer와 output layer를 갯수로 어떤 neural network를 # layer neural network라 부른다.

Computing a Neural Network's Output
logistic regression 같은 경우 한 노드에 두 step의 computation이 있다.
하나는 \( z = w^Tx + b \)를 계산하는 것이고 다른 하나는 \( a = \sigma(z) \)를 계산하는 것이다.

Activation Functions
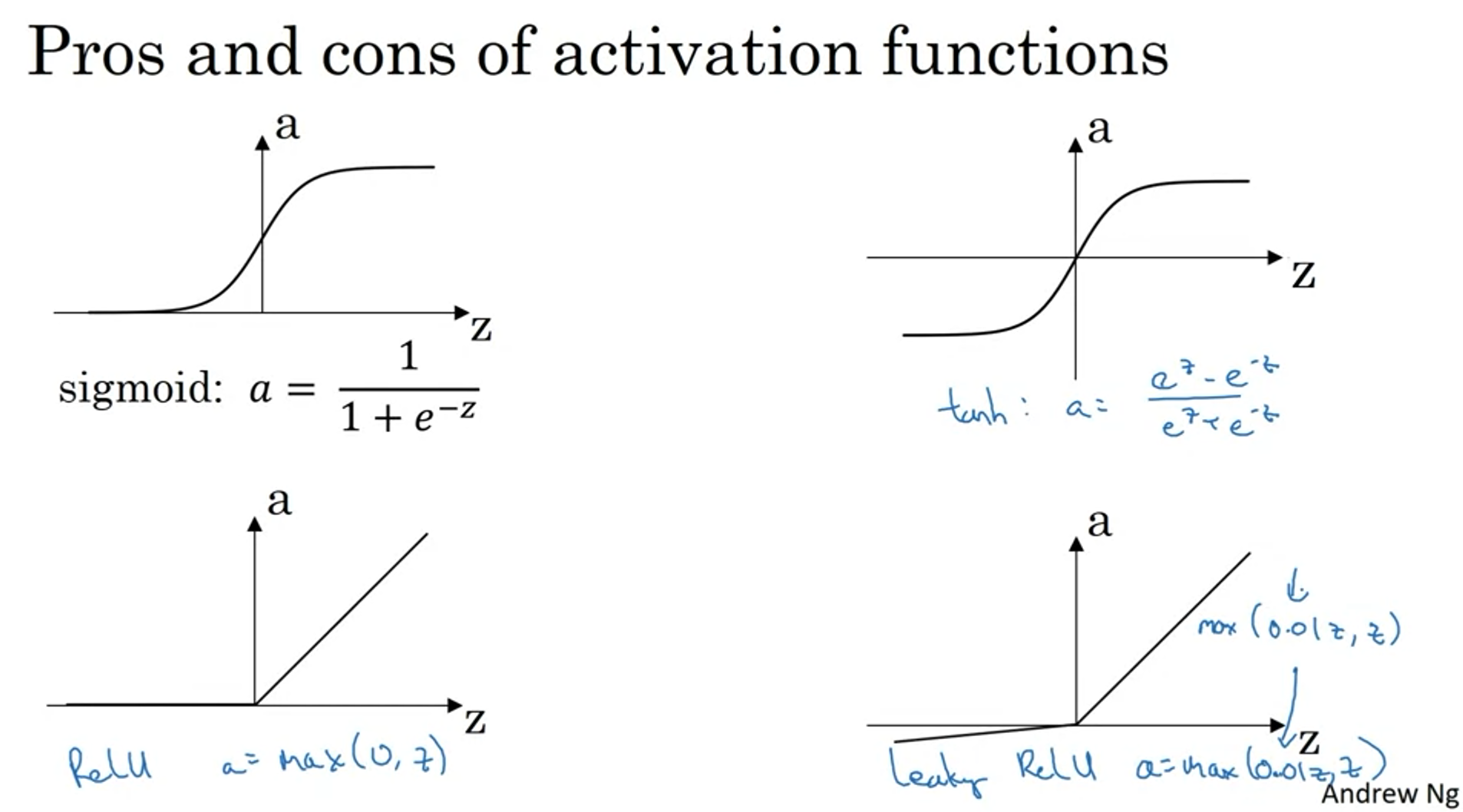
activation function의 종류는 앞선 logistic regression에서 쓴 sigmoid function 이외에도 다양하다.
hyperbolic tangent (tanh), Rectified Linear Unit (ReLU), Leaky ReLU
Why do you need Non-Linear Activation Functions?
이유는 간단한데 몇 겹의 layer를 쌓던지 1 layer로 바꿀 수 있기 때문이다.
1 layer linear regression model만 표현할 수 있다.
Random Initialization
만약 weight를 0으로 initialization 해준다면 같은 layer의 hidden node의 값이 모두 동일할 것이다.
(learning을 해도 derivative가 동일하게 나올 것이기 때문에)
이는 model의 expression power를 해치므로 random initialization을 해주는 것이 좋다.
하지만 여기서도 weight의 각 element의 절댓값이 작아야하는데, 많은 activation function들이 오른쪽이나 왼쪽으로 가면 갈수록 derivative가 0에 가깝기 때문이다.
'Google Machine Learning Bootcamp 2022 > Neural Networks and Deep Learning' 카테고리의 다른 글
| 4. Deep L-layer Neural Network (0) | 2022.07.04 |
|---|---|
| 2. Neural Networks Basics #2 (0) | 2022.06.29 |
| 2. Neural Networks Basics #1 (0) | 2022.06.28 |
| 1. Introduction to Deep Learning (0) | 2022.06.24 |



댓글