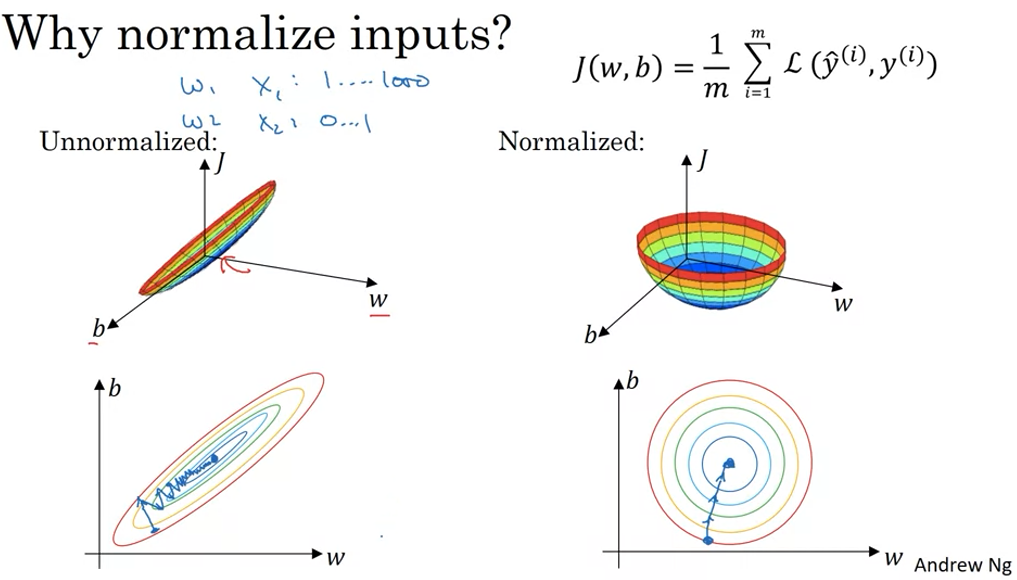
Setting Up your Optimization Problem
Normalizing Inputs
1. Subtract mean
\( \mu = \frac{1}{m} \sum^m_i x^{(i)} \)
\( x := x - \mu \)
2. Normalize variance
\( \sigma^2 = \frac{1}{m} \sum^m_i x^{(i)}*x^{(i)} \)
\( x /= \sigma \)
Vanishing / Exploding Gradients
network가 너무 깊으면 gradient가 너무 작아 사라지거나 너무 커 폭발할 수 있다.
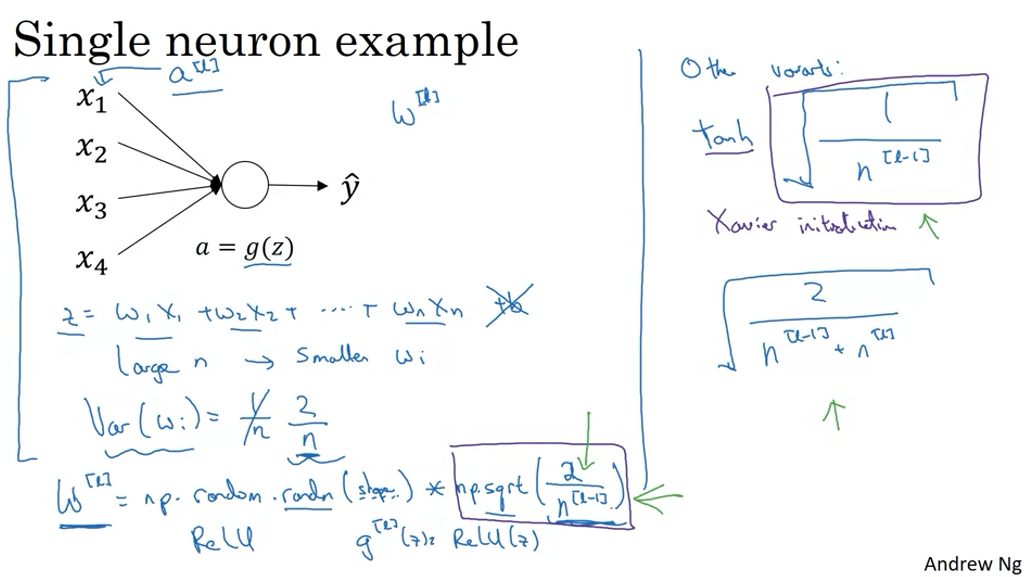
Weight initialization for Deep Networks
Numerical Approximation of Gradients

Gradient Checking

Gradient Checking Implementation Notes
- Don't use in training <- only to debug
- If algorithm fails grad check, look at components to try to identify bug
- If algorithm fails grad check, look at components to try to identify bug.
- Remember regularization
- Doesn't work with dropout
- Run at random initialization; perhaps again after some training
'Google Machine Learning Bootcamp 2022 > Improving Deep Neural Networks' 카테고리의 다른 글
| 3. Hyperparameter Tuning, Batch Normalization and Programming Frameworks (0) | 2022.07.15 |
|---|---|
| 2. Optimization Algorithms (0) | 2022.07.14 |
| 1. Practical Aspects of Deep Learning #2 (0) | 2022.07.06 |
| 1. Practical Aspects of Deep Learning #1 (0) | 2022.07.05 |


댓글