Setting up your Machine Learning Application
Train / Dev / Test sets
Previous: 70% / 30%, 60% / 20% / 20%
Modern: 1M number of data (Big data) -> make dev, test sets as small as possible (ex. 98% / 1% / 1%)
In mismatched train/test distribution, ensure that dev and test come from the same distribution.
Not having a test set might be okay. (Only dev set)
Bias / Variance
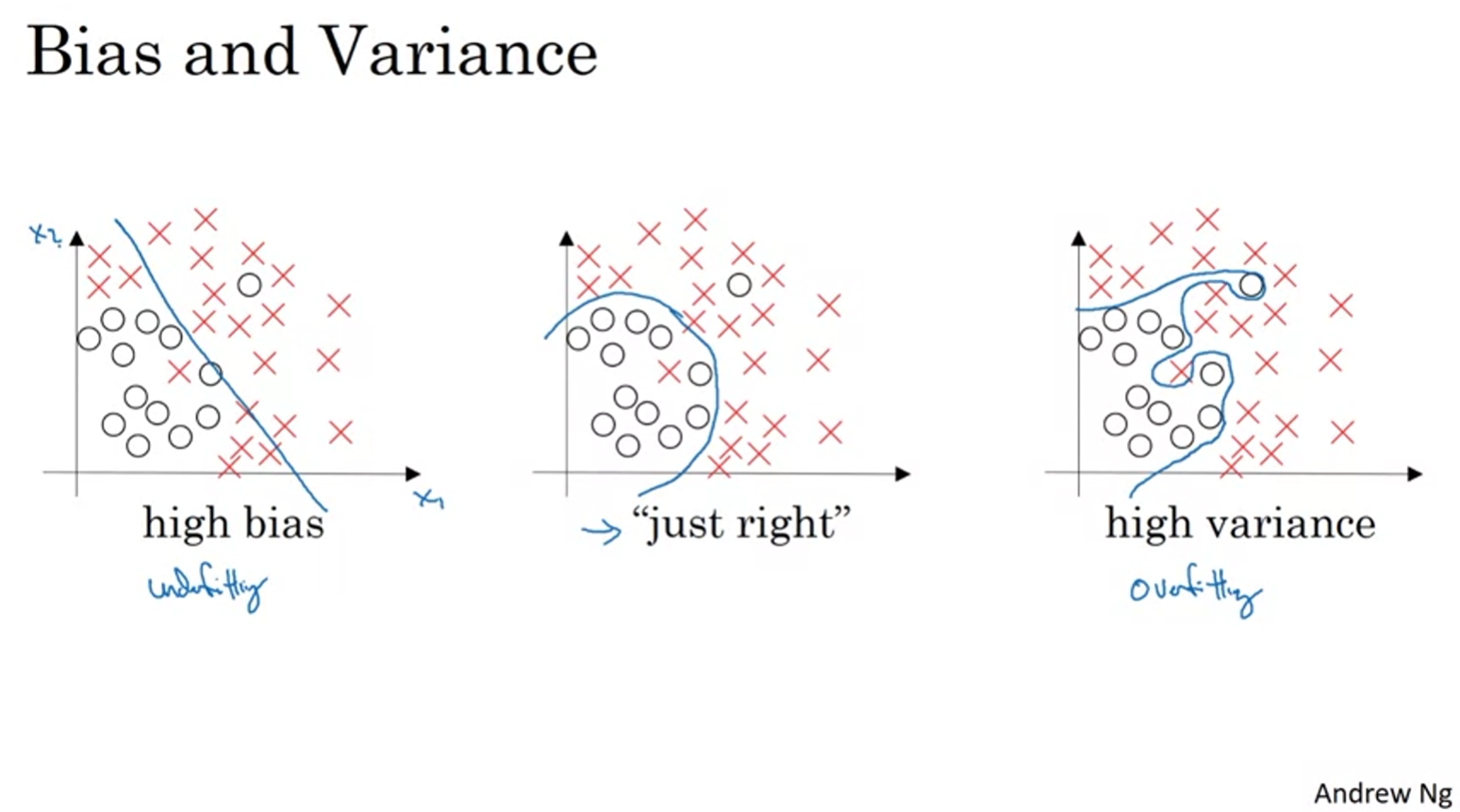

Basic Recipe for Machine Learning
High bias (training data performance) -> bigger network, train longer NN architecture search
High variance (dev data performance) -> more data, regularization, NN architecture search
Previous: "Bias, variance tradeoff"
Modern: Bigger network, More data!
'Google Machine Learning Bootcamp 2022 > Improving Deep Neural Networks' 카테고리의 다른 글
| 3. Hyperparameter Tuning, Batch Normalization and Programming Frameworks (0) | 2022.07.15 |
|---|---|
| 2. Optimization Algorithms (0) | 2022.07.14 |
| 1. Practical Aspects of Deep Learning #3 (0) | 2022.07.10 |
| 1. Practical Aspects of Deep Learning #2 (0) | 2022.07.06 |


댓글